1. 서브쿼리의 개념
서브쿼리란 하나의 쿼리문에서 별도로 사용되고 있는 쿼리 블록을 의미힌다.
즉, 쿼리에 내장된 또 다른 쿼리문이라고 볼 수 있다.
내장된 쿼리문의 위치에 따라 다음과 같이 이름이 불리우게 된다.

ㅇ 스칼라 서브쿼리 : 하나의 레코드당 정확하게 하나의 값을 반환하는 서브 쿼리 (주로 select절에 사용 )
ㅇ 인라인 뷰 : FROM절에 사용
ㅇ 중첩된 서브쿼리 : wHERE절에 사용
위의 쿼리들은 조인을 실행시 해당 쿼리문에서 바로바로 플랜을 형성하지 못한다.
쿼리의 최종 실행단계의 과정에서 옵티마이저는 쿼리를 다양한 형태로 변화시킨후에 최적의 실행계획을 찾아낸다.
그렇기 때문에 서브쿼리 조인을 이해하기 위해서는 쿼리 변환에서부터 찾기 시작해야 하지만, 해당 내용은 복잡하니 추후 다시한번 볼 수 있는 기회가 있으면 좋겠다
2. 서브쿼리와 조인(중첩된 서브쿼리의 조인)
중첩된 서브쿼리에선 아래의 3가지 정도로 실행 게획이 발생할수 있다.
ㅇ 필터 오퍼레이션
해당 처리 방식은 서브쿼리를 필더 방식으로 처리할 때의 실행계획이다.

위의 쿼리를 확인해보면 의도적으로 no_unnest힌트를 사용하여, 서브쿼리를 따로 풀어내지 말고 그대로 수행하라는 힌트를 확인 할수 있다.
그 결과 플랜에서도 서브쿼리를 따로 풀어내지 않았기 대문에 FILTER 방식으로 처리되는 것을 볼 수 있다.
위의 플랜에서 보이는 FILTER방식은 기본적으로 NL조인과 처리 루틴이 같기 때문에 FILTER를 NESTED LOOP로 치환하여 해석할 수 있다.
그렇다면 FILTER와 NESTED LOOP차이점이 궁금할 수 있는데 차이점 약 3가지 존재한다.
1) 메인쿼리의(고객 테이블)의 한 오루가 서브쿼리(거래 테이블)의 한 로우와 조인에 성공하는 순간 진행을 멈춤
(where 조건문의 exists의 의미를 생각하면 쉽게 이해가능)
2) 캐싱기능을 갖는다. 입력값에 따른 반환값(true 또는 False)를 캐싱함. 위릐 캐생 데이터는 PGA에 저장되므로 빠르게 확인가능
3) 조인 순서가 항상 고정. 서브쿼리는 메인쿼리에 항상 종속되므로, 메인쿼리가 항상 드라이빙 집합으로 고정됨
ㅇ 서브쿼리 pushing
no_unnest힌트를 사용한다면 필터 오퍼레이션이 사용된다는걸 앞에서 확인하였고, 이는 대개 실행계획상에서 맨 마지막 단계에 처리된다.
그럼 아래 쿼리를 보면서 어떤 플랜이 나올 지 상상해보자

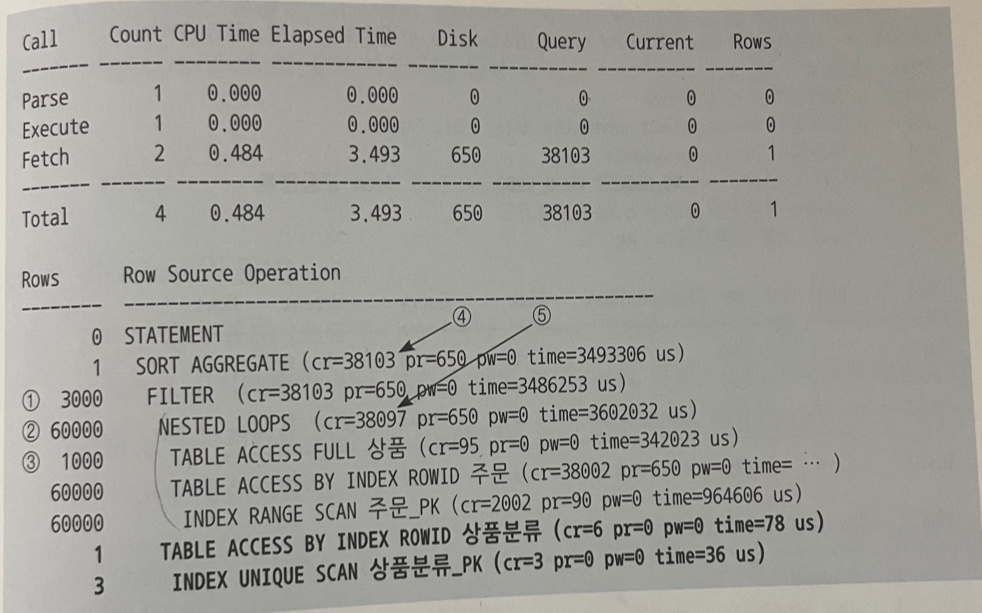
위 쿼리와 플랜을 보면 쿼리문의 WHERE문의 EXSITS 앞까지의 출력되는 컬럼수가 60,000건(②)이며
이후에 서브쿼리로 추가 FILTER를 하면서 3,000건(①) 으로 줄어들었다
위의 쿼리를 보다보면 FILTER를 먼저하여 최초 출력건수를 줄일 수 있지 않을까란 생각을 할 수 있을 것이다.
그럴 때에 사용되는 힌트가 push_subq힌트다.
push_subq힌트에 정리하자면 서브쿼리 필터리링을 가능한 한 앞 단계에서 처리를 강제하는 기능이다.
또한 해당 기능은 UNNEST가 되지 않은 상황(힌트 : NO_UNNEST)에서만 사용가능하니 NO_UNNEST와 같이 사용해주는 편이 좋다

위의 설명대로 해당 힌트 /*+ NO_UNNEST PUSH_SUBQ */를 사용한 걸 볼 수 있다.
서브쿼리 부분을 가장 먼저 체크함으로써 가장 먼저 150건( ① )을 선택하였고, 주문 데이터도 3000건( ② )만 읽은것을 보고 동일 결과를 발생시키는 과정중 더욱 효율적으로 추출하는 것을 볼 수 있었다.
ㅇ 서브쿼리 Unnesting
앞의 두개의 조인 조건은 서브쿼리가 UNNEST가 되지 않았다는 상황에서 처리 가능한 조인들이다.
해당 부분은 앞에서 NL조인, 소트조인, 해시조인을 공부했다면 쉽게 넘어갈 수 있는 부분이다.
왜냐하면 서브쿼리를 UNNEST한다 즉, 메인쿼리와 서브쿼리를 서로 같은 레벨로 만든다는 의미이다.
그리하여 unnest처리 후 어떤 조인을 실행할지는 직접 선언해주면 되기 때문이다.

위의 쿼리를 보면 구조는 서브쿼리으 구조이지만 힌트는 unsset 후 hash (SEMI)조인을 선언하였다 /*+ unnset hash_sj */
그리하여 실제 실행계획을 보면 고객 테이블을 Build부분으로, 거래테이블을 Probe 단계로 본 걸 확인가능하다.
테스트 데이터 생성 방법:
2025.03.20 - [IT/SQLP] - [데이터 생성] 오라클 DB 데이터 생성 쿼리모음(테이블,인덱스,데이터 등)
'IT > SQLP' 카테고리의 다른 글
| [오라클 DB조인] NL조인(Nested Loop)의 원리 및 사용방법(힌트, 플랜) (3) | 2025.03.21 |
|---|---|
| [오라클 DB조인] 해시 조인(Hash Join)의 원리와 사용방법(힌트 및 플랜확인) (1) | 2025.03.21 |
| [오라클 DB조인] 소트 머지 조인(sort Merge Join)의 원리 및 사용방법(힌트 및 플랜 확인) (1) | 2025.03.21 |
| [데이터 생성] 오라클 DB 데이터 생성 쿼리모음(테이블,인덱스,데이터 등) (4) | 2025.03.20 |