1. 소트 머지 조인의 개념
이름 그대로 소트단계, 머지단계 2단계를 거치는 조인 개념이다.
소트단계 : 양쪽의 집합을 각각 조인 컬럼 기준으로 Sort한다.
머지단계 : 이미 정렬한 양쪽 집함을 서로 Merge한다
소트머지 조인이 사용되는 상황으론
1)조인 컬럼에 인덱스가 없을떄,
2)대량 데이터 조인이라 인덱스가 효과를 발휘하지 못할 때
등이 있다.
2. 소트 머지 조인의 동작원리
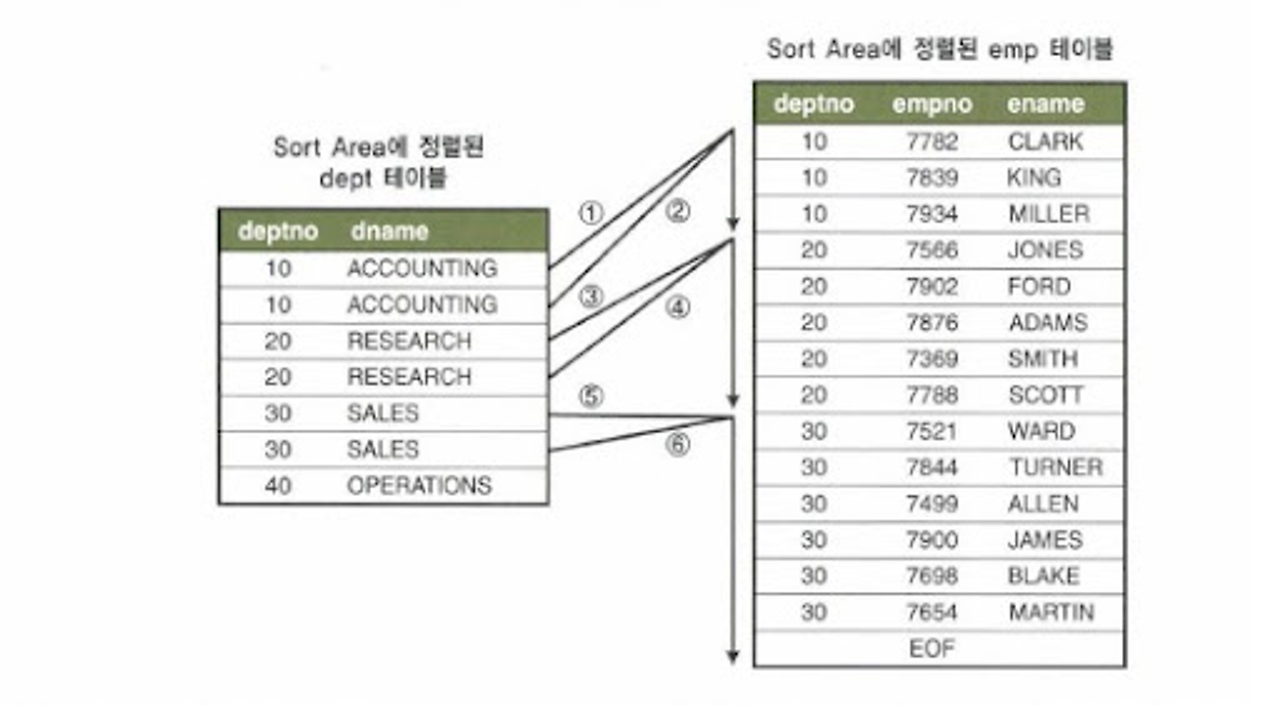
위의 그림에서 살펴보겠다.
1) 위의 그림에서처럼 dept 테이블과 emp테이블을 deptNo컬럼기준으로 정렬한다..
그럼 2개의 테이블이 deptno기준으로 정렬됐음을 확인가능.
2) deptno값이 10인 값을 찾고자 할 때
emp 테이블에서 deptno값이 10인 값을 찾기위해선 10보다 큰수를 만나면 바로 검색을 중간에서 멈출수 있기 때문에
emp 테이블은 전체다 확인하지 않아도 된다
3. 소트머지 조인이 빠른 이유
NL조인의 경우에는 SGA를 통해 데이터를 건건이 읽다보니, 위에서 타 프로세스와 SGA 공간을 획득하는 과정을 계속해서 경쟁해야 한다.
하지만 소트머지 조인은 데이터를 PGA로 들고와서 다른 프로세스와 경쟁없이 데이터를 확인하며 조인이 가능하다.
그런데 위의 빠른 이유를 보다보면 최초에 정렬하여 PGA들고오는 과정도 만만치 않다고 생각할 수 있다.
하지만 이는 소트 머지 조인에서 "대량 데이터"조인에 유리하게 만든 핵심 요인다.
추가로 소트머지조인 의 최초단계인 소트단계에서 테이블을 조회할 때에는 SGA를 통해 데이터를 조회해와햐 한다.
이는 소트머지도 조인도 피할 수 없지만 최초에만 발생하는 단계이므로 이 부분은 감안할 수 있다.
그런데 위에서 PGA, SGA란 단어를 많이 사용했는데 아래에서 그 내용을 추가로 확인해볼 수 있다.
PGA .VS. SGA
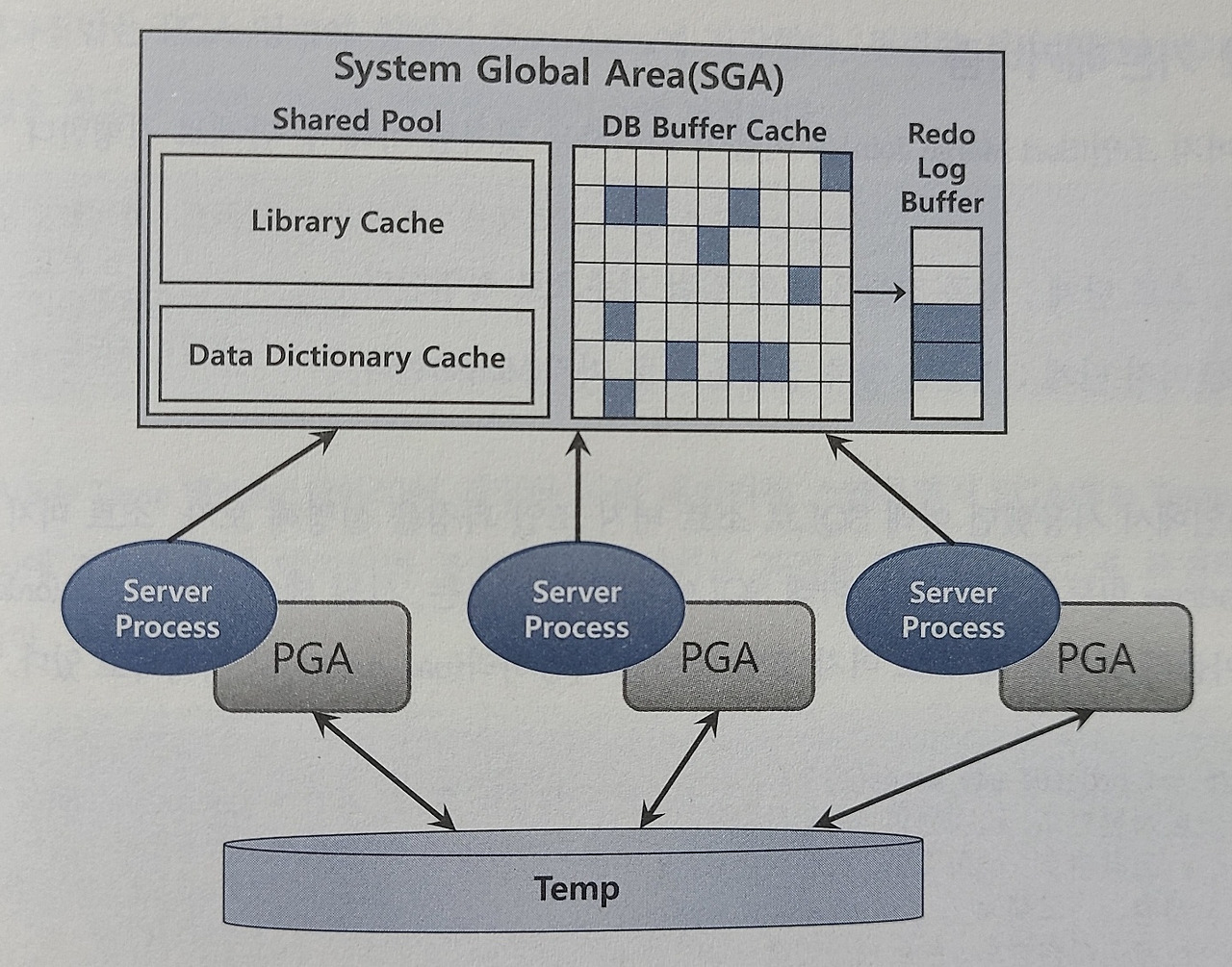
SGA는 모든 프로세스가 공통적으로 사용하는 변수공간이다.
PGA는 그림에서 보다시피 프로세스 각각이 들고이는 변수공간으로 이해하면 된다.
ㅇ SGA
위 공간을 사용하는 데이터를 찾기 위해서는 현재 동작중인 모드 프로세스 들과 경쟁하여 쟁취하여야 한다.그렇기 때문에 매번 데이터를 읽을떄 마다 SGA를 읽게 된다면 시간이 오래 걸릴수밖엔 없다.
(SGA를 차지하기 위해 어떤 경쟁이 일어나는지는 간략히 적어보면
프로세스 간 엑세스를 직렬화하기 위한 LOCK매커니즘인 래치(Latch)를 회득해야하고,
추가로 래치를 획득하고 데이터를 읽으려면 추가로 버러 LOCK도 획득을 필요로 함)
ㅇ PGA
해당 공간은 프로세스마 각자 할당된 공간이기 떄문에 다른 프로세스와의 경쟁이 필요가 없기 떄문에 빠르게 접근이 가능하다
4.소트머지조인 힌트 사용방법
select /*+ use_merge(A) */
from 사원 as A
, 고객 as B
where
use_merge : 소트머지조인을 사용
순서를 정하고 싶을떈 ordered 힌트를 사용하여 정할 수 있음
==>/*+ ordered use_merge(B) */ : A를 시작점으로

사원테이블을 sort하고
고객테이블을 sort하고
두개를 묶어서 merge하는 실행계획 확인가능
5. 소트머지 조인의 특징 마무리 요약
ㅇ 실시간으로 인덱스를 생성하는 것과 다름없다.
양쪽의 집합을 정렬한 다음에 NL조인와 같은 방식으로 진행되고 있지만,이 떄 PGA영역에서 데이터를 이용하기 때문에 속도가 빠르다.
ㅇ 최초에 소트단계를 위해 데이터를 조회할 땐 SGA에서 통해 타 프로세스와 경쟁하여 데이터를 가져오고 있다.
(이는 해시 조인도 동일하다)
'IT > SQLP' 카테고리의 다른 글
| [오라클 DB조인] NL조인(Nested Loop)의 원리 및 사용방법(힌트, 플랜) (3) | 2025.03.21 |
|---|---|
| [오라클 DB조인] 서브쿼리 조인의 원리 및 사용방법(힌트 및 플랜 확인) (1) | 2025.03.21 |
| [오라클 DB조인] 해시 조인(Hash Join)의 원리와 사용방법(힌트 및 플랜확인) (1) | 2025.03.21 |
| [데이터 생성] 오라클 DB 데이터 생성 쿼리모음(테이블,인덱스,데이터 등) (4) | 2025.03.20 |